2020. 12. 1. 21:31ㆍPROJECT/Python_공간데이터분석
1편에서 전처리한 파일을 바탕으로 특정 상호의 분석을 시작한다.
<배스킨라빈스 vs 던킨도너츠 위치 분석>
먼저 전처리한 파일에서 배스킨라빈스 브랜드명을 추출한다.
-> 대소문자가 섞여있을 수도 있기 때문에 대소문자를 변환해준다.
-> 배스킨라빈스/베스킨라빈스가 상호명인 곳을 추출한다.


다음은 던킨도너츠의 갯수를 세어본다.

"배스킨/베스킨/baskin/던킨/dunkin"를 가져와 df_31변수에 담아준다.

브랜드명이 배스킨라빈스가 아닌 데이터를 찾아본다. head()로 데이터 살펴보기

데이터가 제대로 모아졌는지 확인한다.
"상권업종대분류명"의 빈도수를 계산한다.

"소매"와 "생활서비스"가 있다는 게 이상하다 ?
"상권업종대분류명"컬럼에서 "소매", "생활서비스"인 데이터만 가져온다.

"상권업종대분류명"에서 "소매", "생활서비스"는 제외시킨다.

범주형 값으로 countplot을 그린다.
value_counts로 "브랜드명"의 빈도수를 구한다.

normalize=True로 빈도수의 비율을 구한다.

배스킨라빈스와 던킨도너츠의 갯수를 살펴본다.

시군구명으로 빈도수를 세고, 브랜드명으로 색상을 다르게 표현하는 countplot을 그린다.

Pandas의 plot으로 scatterplot을 그린다.

Seaborn의 scatterplot으로 hue에 브랜드명을 지정해서 시각화를 해본다.

위에서 그렸던 그래프를 jointplot으로 kind="hex"을 사용해 그려본다.

Folium으로 지도 활용하기
지도의 중심을 지정하기 위해 위도와 경도의 평균을 구한다.

샘플을 하나 추출해서 지도에 표시해본다.

기본 마커로 표현해본다.(던킨도너츠 매장만)

상호명과 도로명주소를 나타내고, 던킨도너츠는 파란색/ 배스킨라빈스는 빨간색 마커로 나타낸다.

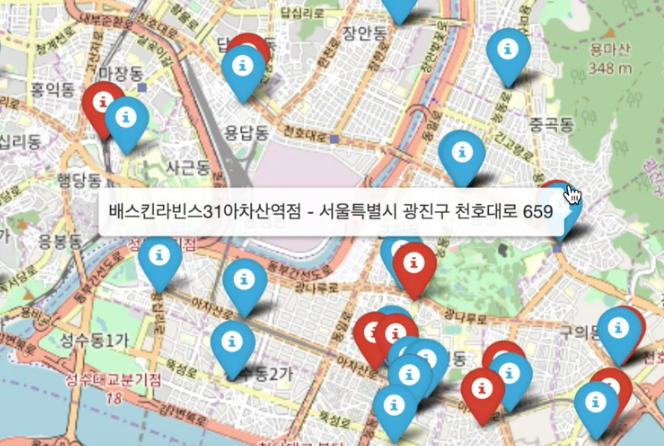
지도로 본 결과 배스킨라빈스 매장이 던킨도너츠에 비해 훨씬 많은 것을 바로 이해할 수 있었다.
마지막으로 MarkerCluster로 표현해보기.

MarkerCluster는 클러스트로 묶어서 데이터를 표현해준다.

지금까지 소상공인시장진흥공단 상가업소정보 데이터를 활용하여 프랜차이즈 분석을 해볼 수 있었다.
이를 응용해서 다양한 프랜차이즈 분석을 할 수 있다.
다음은 파리바게뜨와 뚜레주르... 뒤이어 스타벅스와 이디야를 해본다!
'PROJECT > Python_공간데이터분석' 카테고리의 다른 글
| [서울상권분석] 스타벅스 vs 이디야 매장 위치 비교하기(1편-전처리 과정) (0) | 2020.12.17 |
|---|---|
| [상권 분석] 프랜차이즈 입점분석 (1편-전처리 과정) (0) | 2020.11.29 |
| [서울 상권 분석] 대치동과 목동에는 입시학원이 많을까?(2편) (0) | 2020.11.26 |
| [서울 상권 분석] 대치동과 목동에는 입시학원이 많을까?(1편) (0) | 2020.11.23 |