2020. 12. 17. 22:49ㆍPROJECT/Python_공간데이터분석
이디야커피의 초기입점전략은 "스타벅스 옆"이였다고 한다.
과연 지금도 그럴까?

소상공인시장진흥공단 상가업소정보 데이터를 활용하여 스타벅스와 이디야 매장위치를 비교해본다.
- 텍스트 데이터 정제하기 - 대소문자로 섞여있는 상호명을 소문자로 변경하고 상호명을 추출한다.
- 텍스트 데이터에서 원하는 정보 추출하기 - 브랜드명 컬럼을 만들고 구별매장 수 분석하기
- 데이터 불러오기
공공데이터 포털 : 소상공인시장진흥공단 상가업소정보 데이터 활용
pd.read_csv로 파일을 불러온다.
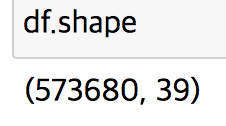
shape를 통해 불러온 csv파일의 크기를 확인한다.
- 데이터 미리보기
df.head()
- info 보기
info를 사용하여 데이터의 전체적인 정보를 본다.(데이터 사이즈, 타입, 메모리 사용량 등)

- 결측치 보기
isnull()을 사용하여 데이터의 결측치를 본다.
결측치는 True로 값이 있다면 False로 표시된다.
True는 1과 같기 때문에 sum()을 사용해서 더하게 되면 합계를 볼 수 있다.

- 사용하지 않는 컬럼 제거하기
사용하는 컬럼만 따로 모아서 사용한다.
'상호명', '상권업종대분류명', '상권업종중분류명', '상권업종소분류명', '시도명', '시군구명', '행정동명', '법정동명', '도로명주소', '경도', '위도'
df.shape를 통해 크기를 확인한다.

또한, info를 사용하여 제거 후 메모리 사용량을 볼 수 있다.

- 색인으로 서브셋 가져오기
- 서울만 따로 보기
시도명이 서울로 시작하는 데이터만 본다.
df.shape를 통해 크기를 확인한다.

- 일부 텍스트가 들어가는 데이터만 가져오기
상호명에서 브랜드명을 추출한다.
대소문자가 섞여있을 수도 있기 때문에 대소문자를 변환해준다.
str.lower()을 이용하여 "상호명_소문자" 컬럼을 만든다.
다음,
df_seoul.loc[df_seoul["상호명_소문자"].str.contains("이디아|이디야|ediya"), "상호명_소문자"]이디야|이디아|ediya
스타벅스|starbucks 를 가져와 갯수를 세어본다.


이디야 : 543개
스타벅스 : 506개 매장이 있는 것을 확인할 수 있다.

"상호명_소문자" 컬럼으로 스타벅스와 이디야커피 데이터를 합쳐준다.
'~'은 not을 의미한다. 결측치를 이디야로 채워준다.

다음편에서는 정제한 텍스트 데이터로 시각화를 해본다!
'PROJECT > Python_공간데이터분석' 카테고리의 다른 글
| [상권 분석] 프랜차이즈 입점분석 (2편-시각화) (0) | 2020.12.01 |
|---|---|
| [상권 분석] 프랜차이즈 입점분석 (1편-전처리 과정) (0) | 2020.11.29 |
| [서울 상권 분석] 대치동과 목동에는 입시학원이 많을까?(2편) (0) | 2020.11.26 |
| [서울 상권 분석] 대치동과 목동에는 입시학원이 많을까?(1편) (0) | 2020.11.23 |